HyDE (Hypothetical Document Embeddings)によるRAGの精度向上
RAGにおけるユーザークエリにより合致するチャンクを取得する方法に、Hyde (Hypothetical Document Embeddings) という手法があります。HyDEでは、ユーザークエリに対して、LLMに仮の回答を生成させ、その回答をもとに関連するチャンクを検索する手法です。

山﨑 祐太
CEO
2024-12-26
2024-12-26
山﨑 祐太
HyDE (Hypothetical Document Embeddings)によるRAGの精度向上
#AI
概要
RAGにおけるユーザークエリにより合致するチャンクを取得する方法に、Hyde (Hypothetical Document Embeddings) という手法があります。HyDEでは、ユーザークエリに対して、LLMに仮の回答を生成させ、その回答をもとに関連するチャンクを検索する手法です。
本記事はRAGの精度改善のための手法であるHyDEを紹介し、またその実装例を示します。
HyDE
HyDEは Precise Zero-Shot Dense Retrieval without Relevance Labels で提案された手法です。
ユーザークエリは通常質問文であり、質問文と回答文で類似検索するよりも、回答文と回答文で類似検索した方が適切なドキュメントを参照できるであろうという仮説から提案されました。
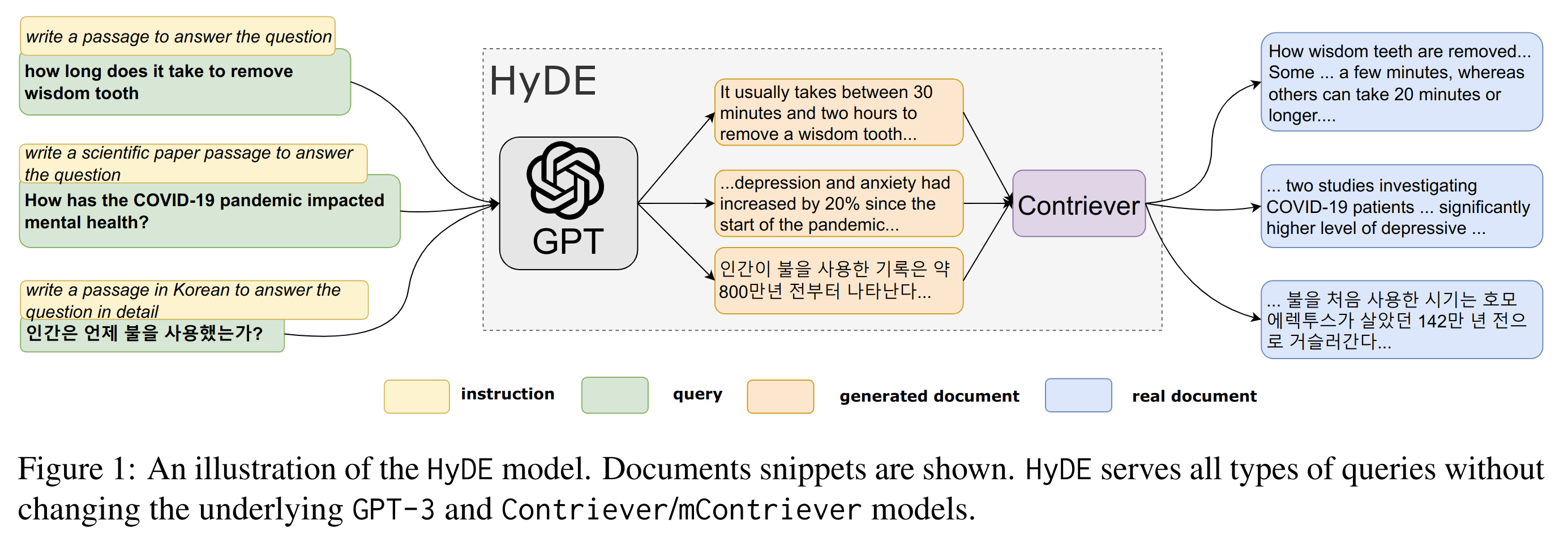
アイデアのシンプルさ、処理の簡単さ、また実際に一定の精度向上が期待できることから、RAGの精度向上において試しやすい手法であると考えられます。
また追加で発生する処理が、ユーザークエリに対して一度だけLLMに回答を作らせるだけなので、実装コストも運用コストも大きく変わらないという利点があります。しかし、LLMに処理を投げることには変わらないため、ユーザーへのレスポンスはその分だけ遅れます。
公式実装である https://github.com/texttron/hyde を見てみると、仮の回答を生成させるためのプロンプトは非常にシンプルなものになっていることがわかります。
WEB_SEARCH = """Please write a passage to answer the question.Question: {}Passage:"""
HyDEを実装する
HyDEの再現に必要なパーツを実装していきます。
主な構成要素は下記の通りです。
- ドキュメントをベクトル化するVectorizer
- ChatGPTのcompletionsAPIをラップしたChatModel
- ドキュメントとベクトルのペアを保持するVectorStore
- 関連ドキュメントを取得するRetriever
import abcimport dataclassesimport typingimport openaidef cosine_similarity(a: list[float], b: list[float]) -> float:if len(a) != len(b):raise ValueError("The length of two vectors must be the same.")dot_product = sum(x * y for x, y in zip(a, b))norm_a = sum(x ** 2 for x in a) ** 0.5norm_b = sum(y ** 2 for y in b) ** 0.5if norm_a == 0 or norm_b == 0:raise ValueError("The norm of a vector must not be zero.")return dot_product / (norm_a * norm_b)@dataclasses.dataclassclass Document:id: str | Nonetext: strmetadata: dict[typing.Any, typing.Any] = dataclasses.field(default_factory=dict)class BaseVectorizer(metaclass=abc.ABCMeta):@abc.abstractmethoddef vectorize(self, text: str) -> list[float]:pass@abc.abstractmethoddef vectorize_batch(self, texts: list[str]) -> list[list[float]]:passclass OpenAIVectorizer(BaseVectorizer):def __init__(self, client: openai.OpenAI, model: str = "text-embedding-3-small") -> None:self.client: openai.OpenAI = clientself.model: str = modeldef vectorize(self, text: str) -> list[float]:r = self.client.embeddings.create(model=self.model,input=[text],encoding_format="float",)return r.data[0].embeddingdef vectorize_batch(self, texts: list[str]) -> list[list[float]]:r = self.client.embeddings.create(model=self.model,input=texts,encoding_format="float",)return [x.embedding for x in r.data]class BaseChatModel(metaclass=abc.ABCMeta):@abc.abstractmethoddef invoke(self, messages: list[dict[str, str]]) -> str:passclass OpenAIChatModel(BaseChatModel):def __init__(self, client: openai.OpenAI, model: str = "gpt-4o-mini") -> None:self.client: openai.OpenAI = clientself.model: str = modeldef invoke(self, messages: list[dict[str, str]]) -> str:r = self.client.beta.chat.completions.parse(model=self.model,messages=messages,)message: str = r.choices[0].message.contentreturn messageclass BaseVectorStore(metaclass=abc.ABCMeta):@abc.abstractmethoddef search(self, query: str, **kwargs) -> list[Document]:passclass InMemoryVectorStore(BaseVectorStore):def __init__(self, vectorizer: BaseVectorizer) -> None:self.documents: list[tuple[Document, list[float]]] = []self.vectorizer: BaseVectorizer = vectorizerdef add(self, documents: list[Document], vectors: list[list[float]] | None = None) -> None:for i, doc in enumerate(documents):if vectors is not None:vector = vectors[i]else:vector = self.vectorizer.vectorize(doc.text)self.documents.append((doc, vector))def search(self, query: str, k: int = 1) -> list[Document]:candidates: list[tuple[Document, float]] = []query_vector = self.vectorizer.vectorize(query)for doc, vector in self.documents:similarity = cosine_similarity(vector, query_vector)print(similarity, doc.text)candidates.append((doc, similarity))top_k = sorted(candidates, key=lambda x: x[1], reverse=True)[:k]return [doc for doc, _ in top_k]class BaseRetriever(metaclass=abc.ABCMeta):@abc.abstractmethoddef retrieve_relevant_documents(self, query: str) -> list[Document]:passclass HyDERetriever(BaseRetriever):def __init__(self,vector_store: BaseVectorStore,chat_model: BaseChatModel,k: int,) -> None:self.vector_store: BaseVectorStore = vector_storeself.language_model: BaseChatModel = chat_modelself.k: int = kdef retrieve_relevant_documents(self, query: str) -> list[Document]:base_propmt: str = """簡潔な文章で回答してください。質問:{0}回答:"""prompt: str = base_propmt.format(query)rephrased_text = self.language_model.invoke([{"role": "system", "content": prompt}])print(rephrased_text)return self.vector_store.search(rephrased_text, k=self.k)class SimpleRetriever(BaseRetriever):def __init__(self, vector_store: BaseVectorStore, k: int) -> None:self.vector_store: BaseVectorStore = vector_storeself.k: int = kdef retrieve_relevant_documents(self, query: str) -> list[Document]:return self.vector_store.search(query, k=self.k)
ChatGPTのモデルとして、gpt-4o-miniを使用します。このモデルは2023年10月までのデータで学習されているため、それ以降の情報が含まれる質問でテストします。今回のユーザークエリは下記の通りです。
user_prompt: str = "鎌田大地選手の所属クラブはどこですか。"
RAGで使用する参考文書は、 https://ja.wikipedia.org/wiki/鎌田大地 の一節です。
text: str = """鎌田 大地(かまだ だいち、1996年8月5日 - )は、日本のプロサッカー選手。プレミアリーグ・クリスタル・パレスFC所属。ポジションはミッドフィールダー。日本代表。弟はサッカー選手の鎌田大夢。大阪府岸和田市生まれ、愛媛県伊予市出身。来歴プロ入り前大学サッカー名門の大阪体育大学でサッカーを専修していた父・幹雄が高い技術力のある選手を目指し、父の教えで3歳からサッカーを始める。3歳でクワトロ(キッズFCの前身)に入団。キッズFC(現・FCゼブラキッズ)では小学5年時に一学年上のナショナルトレセンU-12四国に選出。キャプテンだった小学6年時には、愛媛県少年サッカー選手権大会で優勝。中学からは、大阪府岸和田市に住む祖父母の家から通える距離にあったガンバ大阪ジュニアユースに進んだ。しかし主戦場であるトップ下のポジションには井手口陽介ら多くのライバルがいた。鎌田は中学入学時に小柄で150cm程だったが、3年間で175cmまで伸び、成長に筋肉が追いつかず、思うようなプレーができない「クラムジー」に陥り、中学1年生時に腕の骨、中学3年生夏の全国大会直前には腰の骨を骨折した影響もあり思うようなパフォーマンスが発揮できず、中3になっても途中出場が多かった。守備面やハードワーク面での物足りなさも指摘され、ユースへの昇格は叶わなかった。 中学一年時の2009年にJOMOカップU-13Jリーグ選抜に選出され、韓国戦に出場。この時、同じ小学校でキッズFCのチームメイトだった山本亮太が愛媛FCジュニアユースから選出されている。"""
引用「鎌田大地 ウィキペディア (Wikipedia): フリー百科事典 最終更新日時 2024年12月16日 (月) 03:16」
まずはRAGを使用せずに、そのままChatGPTへクエリを投げてみます。
import openaiimport coreos.environ["OPENAI_API_KEY"] = "sk-proj-xxx"if __name__ == "__main__":client = openai.OpenAI()chat = core.OpenAIChatModel(client, model="gpt-4o-mini")user_prompt: str = "鎌田大地選手の所属クラブはどこですか。"system_propmt: str = "ユーザーの質問に回答してください。"messages = [{"role": "system","content": system_propmt,},{"role": "user","content": user_prompt,},]response = chat.invoke(messages)print("Chat Response:\\n", response, "\\n")
Chat Response:鎌田大地選手は、2023年時点でドイツのフランクフルトに所属しています。ただし、選手の移籍状況は変わることがあるため、最新の情報を確認することをお勧めします。
鎌田選手は2023年8月にフランクフルトからラツィオへ移籍していますが、概ねその当時の情報を元に回答できています。しかし2024年12月時点では、クリスタル・パレスFCに移籍しています。
次にRAGでHyDEを用いた実装を試してみます。
import jsonimport osimport openaifrom langchain_text_splitters import RecursiveCharacterTextSplitterimport coreos.environ["OPENAI_API_KEY"] = "sk-proj-xxx"EMBEDDING_MODEL = "text-embedding-3-small"VECTOR_DB_PATH = "vectorDB.json"if __name__ == "__main__":text_splitter = RecursiveCharacterTextSplitter(chunk_size=200,chunk_overlap=20,length_function=len,is_separator_regex=False,)text: str = """鎌田 大地(かまだ だいち、1996年8月5日 - )は、日本のプロサッカー選手。プレミアリーグ・クリスタル・パレスFC所属。ポジションはミッドフィールダー。日本代表。弟はサッカー選手の鎌田大夢。大阪府岸和田市生まれ、愛媛県伊予市出身。来歴プロ入り前大学サッカー名門の大阪体育大学でサッカーを専修していた父・幹雄が高い技術力のある選手を目指し、父の教えで3歳からサッカーを始める。3歳でクワトロ(キッズFCの前身)に入団。キッズFC(現・FCゼブラキッズ)では小学5年時に一学年上のナショナルトレセンU-12四国に選出。キャプテンだった小学6年時には、愛媛県少年サッカー選手権大会で優勝。中学からは、大阪府岸和田市に住む祖父母の家から通える距離にあったガンバ大阪ジュニアユースに進んだ。しかし主戦場であるトップ下のポジションには井手口陽介ら多くのライバルがいた。鎌田は中学入学時に小柄で150cm程だったが、3年間で175cmまで伸び、成長に筋肉が追いつかず、思うようなプレーができない「クラムジー」に陥り、中学1年生時に腕の骨、中学3年生夏の全国大会直前には腰の骨を骨折した影響もあり思うようなパフォーマンスが発揮できず、中3になっても途中出場が多かった。守備面やハードワーク面での物足りなさも指摘され、ユースへの昇格は叶わなかった。 中学一年時の2009年にJOMOカップU-13Jリーグ選抜に選出され、韓国戦に出場。この時、同じ小学校でキッズFCのチームメイトだった山本亮太が愛媛FCジュニアユースから選出されている。"""chunks = text_splitter.create_documents([text])documents: list[core.Document] = []client = openai.OpenAI()vectorizer = core.OpenAIVectorizer(client, model=EMBEDDING_MODEL)vector_store = core.InMemoryVectorStore(vectorizer=vectorizer)if not os.path.exists(VECTOR_DB_PATH):documents = [core.Document(id=str(i), text=c.page_content) for i, c in enumerate(chunks)]vectors = vectorizer.vectorize_batch([c.page_content for c in chunks])vector_store.add(documents, vectors)import jsondata = {"documents": [{"id": doc.id, "text": doc.text, "metadata": doc.metadata} for doc in documents],"vectors": vectors}with open(VECTOR_DB_PATH, "w") as f:json.dump(data, f)else:with open(VECTOR_DB_PATH) as f:data = json.load(f)documents = [core.Document(id=d["id"], text=d["text"], metadata=d["metadata"]) for d in data["documents"]]vectors = data["vectors"]vector_store.add(documents, vectors)user_prompt: str = "鎌田大地選手の所属クラブはどこですか。"chat = core.OpenAIChatModel(client, model="gpt-4o-mini")hyde_retriever = core.HyDERetriever(vector_store, chat, k=2)response = hyde_retriever.retrieve_relevant_documents(query=user_prompt)system_propmt: str = """以下の文脈を利用して、質問に回答してください。文脈:{}""".format("\\n".join([doc.text for doc in response]))messages = [{"role": "system","content": system_propmt,},{"role": "user","content": user_prompt,},]response = chat.invoke(messages)print("Chat Response:\\n", response)
Chat Response:鎌田大地選手の所属クラブは、プレミアリーグのクリスタル・パレスFCです
2024年12月時点での適切な回答が得られました。
HyDEによるクエリの言い換えでは、下記のクエリが得られています。
鎌田大地選手の所属クラブはフランクフルトです。
ここから関連文書の取得時には、下記の2つのチャンクを関連度が高いとして取得しています。1つ目のチャンクがまさに所属クラブを示すものであり、適切な情報が取得できていることがわかります。
0.5588660754118504鎌田 大地(かまだ だいち、1996年8月5日 - )は、日本のプロサッカー選手。プレミアリーグ・クリスタル・パレスFC所属。ポジションはミッドフィールダー。日本代表。弟はサッカー選手の鎌田大夢。大阪府岸和田市生まれ、愛媛県伊予市出身。
0.36660476400566566中学からは、大阪府岸和田市に住む祖父母の家から通える距離にあったガンバ大阪ジュニアユースに進んだ。しかし主戦場であるトップ下のポジションには井手口陽介ら多くのライバルがいた。鎌田は中学入学時に小柄で150cm程だったが、3年間で175cmまで伸び、成長に筋肉が追いつかず、思うようなプレーができない「クラムジー」に陥り、中学1年生時に腕の骨、中学3年生夏の全国大会直前には腰の骨を骨折した影響もあり
まとめ
本記事では、RAG(Retrieval-Augmented Generation)の精度向上手法であるHyDE(Hypothetical Document Embeddings)を紹介し、その実装例を詳しく解説しました。
HyDEは、ユーザークエリに対して生成された仮想回答を基に関連する情報を検索するというアプローチを採用しています。
これによって、関連する文書をより関連しやすく評価でき(シグナルを捉えやすくなる)、関連しない文書をより遠ざけられる(ノイズを削減できる)という効果が得られる可能性があります。
当社では、最新のAI技術を活用したソリューション開発に注力しており、データ活用の課題解決や業務効率化を支援しています。RAGによるチャットボットにご興味がある方は、ぜひお気軽にお問い合わせください。
Share



Author
山﨑 祐太
CEO
神⼾⼤学と神⼾⼤学⼤学院にて深層学習に関する研究を⾏い、⼤阪のAI ベンチャーで機械学習エンジニアとして従事。株式会社Digeonを創業。