ModernBERT - 高精度で高速化なBERT
BERTを改良し、高速かつGLUEに優れるModernBERTが提案されました。本記事では、ModernBERTについて解説します。

山﨑 祐太
CEO
2024-12-21
2024-12-21
山﨑 祐太
ModernBERT - 高精度で高速化なBERT
#AI
目次
概要
BERTを改良し、高速かつGLUEに優れるModernBERTが提案されました。
- 公式ブログ → Finally, a Replacement for BERT: Introducing ModernBERT
- 論文 → Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
- GitHub → AnswerDotAI/ModernBERT: Bringing BERT into modernity via both architecture changes and scaling
本記事では、ModernBERTについて解説します。
ModernBERTの背景
BERT
2018年に発表されたBERTは、自己教師あり学習とTransformerベースのアーキテクチャを採用し、NLPタスクで当時の最先端モデルを大幅に上回る成果を示しました。
BERT(およびその派生系のモデル)は、ChatGPTなどの大規模言語モデル(LLM)が全盛の2024年12月現在も、検索におけるEmbeddingや、文書分類、エンティティ抽出、音声合成など、広く使用されています。
LLMとBERT
現在はChatGPTやGeminiなど、LLMが研究や開発の分野で盛んに取り沙汰されています。これらのモデルはいわゆる生成AIであり、Decoder-onlyなモデルです。LLMと呼ばれるほどに膨大なパラメータを持ち、処理が重く、処理すべき文書が多い場合、非常にコストが高くつきます。
こういったケースでは今なおBERT派生のEncoder-onlyなモデルが広く利用されています。公式ブログ内では、手頃で信頼性が高く便利であるBERT派生のモデルをホンダシビック、LLMをフェラーリで例えられていました。
ModernBERTのモチベーション
近年のLLMに関する研究の発展により、様々な高速化や精度向上のための取り組みが提案されてきました。本研究ではそれらの要素を取り入れ、LLMよりも手軽に使えるBERTを、高速かつ高精度に進化させるべく提案されています。
ModerBERTの解説
何がすごいか
ModernBERTは従来のBERT派生のモデルよりもGLUEで大きく優れ、また非常に高速に動作します。ModernBERTではBASE(149M parameters)とLARGE(395M parameters)という2種類のモデルが提案されており、BASEでは比較されている派生モデルのどれよりも処理速度が速く、ROBERTA-LARGEに匹敵するほどのGLUEスコアを誇ります。
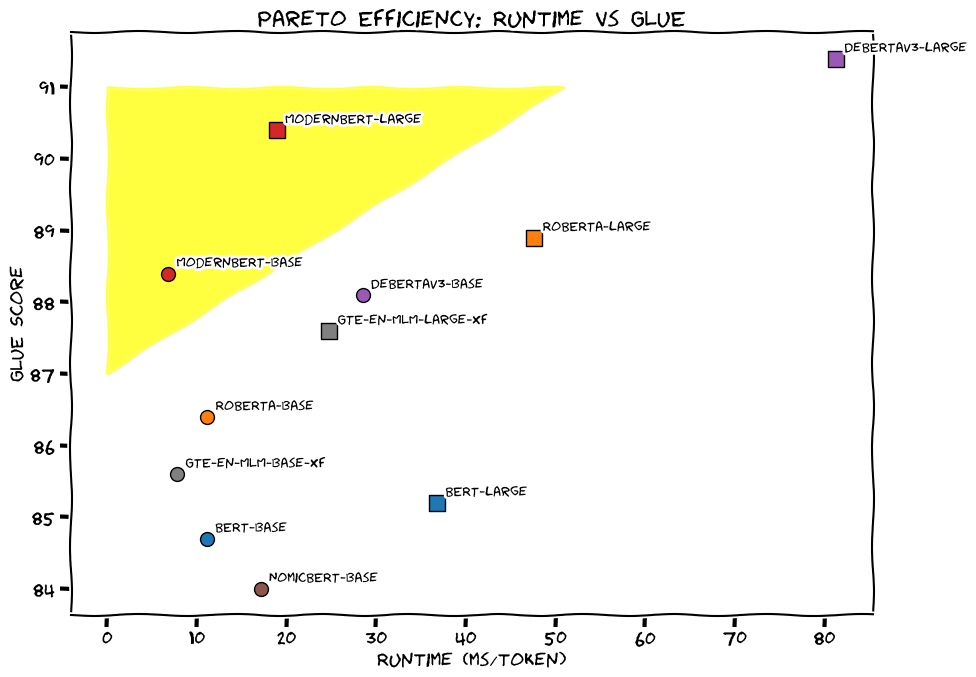
またBERTや多くの派生モデルはtokenのSequence Lengthが512でしたが、ModernBERTは8192のトークンを処理することができます。これによってより長い文章を処理できることになり、検索用途におけるチャンクサイズ調整に幅を持たせることができます。
ModernBERTは多くの評価タスクにおいて、優れたパフォーマンスを発揮しています。
.png)
アーキテクチャの改良
Positional EncodingをRoPEに置き換える
RoPE(Rotary Positional Embeddings)は RoFormer: Enhanced Transformer with Rotary Position Embedding ではじめて提唱された手法です。Positional EncodingをRoPEにすることで、単語同士の関係を正確に理解し、より長いトークンを扱えるようになりました。
Attentionの変更
最初の3層はGlobal Attentionを採用して全てのトークンを注目し、その後の全ての層ではLocal Attentionとして前後128個のトークンのみに注目するような変更を加えています。
Global Attentionでは、全ての単語に注目するため、トークンが追加される毎に計算量が増大します。そこをLocal Attentionに切り替えることで、より大きなトークン数を高速に処理することができるようになりました。
.png)
人間が書籍を読むときに全ての文章に注目しながらではなく、現在の章に注目していれば十分読めるだろう、という着想からLocal Attentionを採用しているようです。
Unpadding
従来のEncoderモデルでは、バッチ内の長さを揃えるために、バッチ内で最も長いものに合わせてパディングをして、並列計算を可能にしていました。しかしパディングは意味のないトークンであり、その度に意味のない計算が実行されていることになります。
ModernBERTでは、MosaicBERTのように、学習時と推論時の両方で、Unpaddingを使用します。
.png)
Flash Attentionの導入
ModernBERTは、Global AttentionにはFlash Attention 3を、Local AttentionにはFlash Attention 2を使用しています。
その他の変更点
- 活性化関数をGeLUからGeGLUに変更
- 不要なバイアス項の削除によるパラメータ効率化
- 学習を安定させるためにpost-LayerNormをpre-normalization blockに変更
- またEmbeddingの直後にLayerNormを追加している
学習データの改良
従来のEncoderモデルでは、WikipediaやWikibooksなどの限られたコーパスで学習されていました。これらのデータは比較的高品質であり学習データに多様性がないことから、本手法ではWeb文書、ソースコード、論文などの様々な英文で構成されたコーパスで学習しています。
これによってDeBERTaV3では約1兆のトークンで学習されていたのが、約2兆のトークンで学習されており、多様な下流タスクで良い精度が出せるようになっています。
学習方法
基本的にはBERTの学習方法と同様ですが、Next Sentence Predictionは明確な利点がないことから学習せず、Maskするトークンの割合を15%から30%に引き上げています。
3段階で学習を行なっており、最初はシーケンス長を1024、1.7Tトークンで学習させ、次に長いコンテキスト長に対応できるようにシーケンス長を8192(ModernBERTのシーケンス長と同じ)にして250Bトークンで学習させています。最後にProLongと同様に、長い文章と短い文章を混ぜ合わせた 50B トークンで学習させることで、長短両方の文章で適切に文書を理解できるようになりました。
また学習の初期段階ではランダムに設定されたパラメータを更新するために、バッチサイズウォームアップを採用しています。特に初期にモデルの重み更新を頻繁にし、初期のパラメータ調整を高速化しています。
ModernBERT-BASEの重みをModernBERT-LARGEの初期値として採用し、ランダムな値で初期化するよりも効率的に学習できるようにしています。
fine-tuning
このモデルはあくまで英語で学習されているだけであり、日本語で使用する場合や、英語でもRAGなどの検索で使用するケースでは、それに合わせたfine-tuningが必要になる点は注意です。
ModernBERTを動かす
Hugging Faceのサンプルコード
https://huggingface.co/answerdotai/ModernBERT-base に記載のコードをのFranceをJapanに変更して動かしてみます。
from transformers import AutoTokenizer, AutoModelForMaskedLMif __name__ == "__main__":model_id = "answerdotai/ModernBERT-base"tokenizer = AutoTokenizer.from_pretrained(model_id)model = AutoModelForMaskedLM.from_pretrained(model_id)text = "The capital of Japan is [MASK]."inputs = tokenizer(text, return_tensors="pt")outputs = model(**inputs)# To get predictions for the mask:masked_index = inputs["input_ids"][0].tolist().index(tokenizer.mask_token_id)predicted_token_id = outputs.logits[0, masked_index].argmax(axis=-1)predicted_token = tokenizer.decode(predicted_token_id)print("Predicted token:", predicted_token)
$ python main.pyPredicted token: Tokyo
参考文献
- 公式ブログ → Finally, a Replacement for BERT: Introducing ModernBERT
- 論文 → Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
- GitHub → AnswerDotAI/ModernBERT: Bringing BERT into modernity via both architecture changes and scaling
Share



Author
山﨑 祐太
CEO
神⼾⼤学と神⼾⼤学⼤学院にて深層学習に関する研究を⾏い、⼤阪のAI ベンチャーで機械学習エンジニアとして従事。株式会社Digeonを創業。