Transformerの解説
Transformerは、Googleが2017年に発表したニューラルネットワークモデルで、機械翻訳の精度向上に貢献しました。本記事では、Transformerの構造やAttention機構、学習手法について詳しく解説し、BERTやGPTといった後のAIモデルの基盤としての重要性を説明しています。

芝 紘希
ソフトウェアエンジニア
2025-2-21
2025-2-21
芝 紘希
Transformerの解説
#AI
目次
- 概要
- 1. Transformerのアーキテクチャ
- 2. Attention
- 2.1 Attentionとは
- 2.2 Seq2Seq に Attention を組み込む
- 2.3 query-key-value
- 2.4 Self-attention(Intra-attention)とCross-attention(External-attention)
- 2.5 Scaled Dot-Product Attention
- 2.6 Multi-Head Attention
- 3. Position-wise feed-forward
- 4. Embeddings と Positional encoding
- 4.1 トークン埋め込み
- 4.2 位置埋め込み
- 5. 学習を安定化させる様々な仕組み
- 5.1 residual connection
- 5.2 LayerNorm
- 5.3 Dropout
- 6. Encoder
- 7. Decoder
- 8. Transformerの学習
- 8.1 Teacher forcing
- 8.2 Masked Multi-Head Attention
- 9. まとめ
概要
本記事ではTransformerについてお話します!
TransformerはGoogleが2017年に発表した論文"Attention Is All You Need"で提案された機械翻訳のモデルです。当時の翻訳に関するベンチマークBLEUにおいて他の手法を上回りました。
また、Transformerは後に発表されるBERTやGPTといった有名なモデルのベースにもなっています。そのため今後の生成AIのトレンドを追うのにTransformerの理解は必要不可欠です。
1章でTransformerの全体像をざっくりと紹介した後、2章から5章でTransformerを構成するコンポーネントについて理解を深めていきます。そして6, 7章でTransformerを構成するEncoder・Decoderの説明を再び行い、モデルの内容を完璧に理解します。最後に8章でTransformerの学習がどのように工夫されているかを紹介します。
1. Transformerのアーキテクチャ
この章ではTransformerのアーキテクチャを紹介します。
TransformerはEncoder-Decoderモデルです。当時のSeq2Seqのようなsequence transductionモデル(時系列変換モデル)ではよく採用されていました。
Encoderは、Input Embedding+Positional Encoding+Encoder Layer(6層)で構成されます。Encoder Layerは2つの副層、Multi-Head Attention(Self-attention) Layer及びFeed Forward Layerからなります。各副層ではresidual connection(残差接続)及びLayerNorm(層正規化)を行なっています。残差接続を複数回使用する都合上、モデル内の全ての副層(埋め込み層も含め)の出力の次元は$d_{model}=512$となっています。
Decoderは、Output Embedding+Positional Encoding+Decoder Layer(6層)で構成されている。Decoder Layerでは3つの副層、Masked Multi-Head Attention(Self-attention) Layer及びMulti-Head Attention(Cross-attention) Layer, Feed Forward Layerからなります。デコーダでも各副層において残差接続及び層正規化を行なっています。
最後にDecoderからの出力をターゲット言語のトークン列に関する確率に変換します。この変換はLinear層及びSoftmax層からなるクラス分類器で行われます。ここでの処理は、クラス分類を行う一般的なニューラルネットワークと同じです。
2章以降では以下の主要なコンポーネントについて詳しく見ていきます。
- Attention
- Position-wise Feed-Forward Networks
- Token Embedding and Positional Encoding
- residual connection, LayerNorm, Dropout
2. Attention
Transformer で用いられるアイデアで最も重要なものは Attention (Attention mechanism) です。これは論文のタイトル「Attention Is All You Need」からも明らかでしょう。
この章では Transformer を理解する上で避けては通れない Attention について紹介していきます!
2.1 Attentionとは
Attention は日本語で「注意」と訳されます。今回のTransformerの文脈においても同じような意味を持ちます。Attention を用いて「ある時系列データの各要素についてどの要素に注意すべきか、つまりどの要素が重要か」をモデルは理解します。
機械翻訳のような「文章から文章を生成するモデル」にAttentionを使用する例を考えます。「私はペンを持っている」という文章を英訳します。我々人間が翻訳する際、単語「ペン」は英語で「pen」である、ということを頭の中で考えながら翻訳します。このように「ペン = pen」のような単語の対応関係を表す情報は アライメント と呼ばれ、人が翻訳を行う際に重要な手掛かりとなります。これと同じようなことを行う機構がTransformerでいうAttentionです。
具体的には、Attention層はデコーダが注意すべきエンコーダの出力を教えてくれます。「I have a XXX」のXXX = penを予測するときには、入力列の「ペン」をエンコードした値hidden state(隠れ状態)に注意を置くべきだとAttentionは教えてくれます。
抽象的には、入力列の各埋め込み列(ベクトル)に対し、それぞれの重要度を考慮して重み付き和を計算します。
2.2 Seq2Seq に Attention を組み込む
図2.2.1は前回紹介したSeq2Seqモデルのアーキテクチャです。
エンコーダでは日本語での入力列「私はペンを持っている」からそれぞれの隠れ状態 $h_0, h_1, ..., h_{T-1} $ を計算します。そして最後の文字を処理した後の隠れ状態 $h_{T-1}$ がデコーダに渡されます。
デコーダに渡されるベクトル(hidden state)の大きさ(次元)は入力列の長さが8の場合でも32の場合でも同じです。つまりデコーダが入力列から得られる情報量は入力された文章の長さに関係しません。これは少し直感から外れてしまっています。「私はペンを持っている」と「私は三宮のジュンク堂で購入した赤色のペンを持っている」という二つの文章がもつ情報量は明らかに異なります。そのため入力列の長さ(トークン数)に応じて、デコーダの知ることができる情報量を調整する必要がありそうです。

この問題を解決するために、隠れ状態の全て $\bm{h^{en}} = [h_0, h_1, ..., h_{T-1}] $ をデコーダに渡すように修正します!
この修正に伴い、Seq2Seqモデルの構造を図2.2.2のように変更します。デコーダに全ての隠れ状態 $\bm{h^{en}}$ を渡すように変更しました。$\bm{h^{en}}$ はAttention層の入力の一つとして利用されます。ただしデコーダ内部にある先頭のLSTM層に渡す値は $h_{T-1}$ の一つのままです。

次に Attention を利用する場合のデコーダの構造について詳しく見ていきましょう。図2.2.3がその構造です。以前に加えてAttention層が追加されました。そして、このAttention層の入力にエンコーダの隠れ状態全体である $\bm{h^{en}}$ が用いられます。また、Affine層の入力には、LSTM層からの出力とAttention層からの出力を結合(concat)したものを使用します。

次にAttention層の内部を見ていきましょう!
t番目のAttention層への入力は、エンコーダの隠れ状態全体 $\bm{h^{en}} = [h_0, h_1, ..., h_{T-1}]$ と、時刻tのデコーダの隠れ状態 $h^{de}_{t}$ です。デコーダの隠れ状態$h^{de}_{t}$を用いて、複数あるエンコーダの隠れ状態のうちのどの隠れ状態に注意すべきかを計算します。
Attention層での処理は大きく分けて二つあります。
1つ目は$\bm{h^{en}}$のそれぞれの要素$h_i$に対する重み$w_i$を計算することです。今回のタスク(日本語から英語への翻訳)における重みは、入力単語(日本語)と出力単語(英語)の類似度を表したものが良いでしょう。これは2.1節で説明したアライメントを想像してください。ベクトル同士の類似度の計算には「ベクトル同士の内積」を使用します。具体的には、エンコーダの各隠れ状態$h^{en}_i(i = 0, 1, ..., T-1)$に対して次のような計算を行います。
$$ w_i = h^{en}_i \cdot h^{de}_t $$
そして全ての隠れ状態に対して重み$w_i$を計算した後、Softmax関数を適用して0から1の範囲に収まるように重みを修正します。
2つ目は求めた重み$w_i$とエンコーダの隠れ状態$h_i$を掛け合わせて重み付き和 $c$ を計算することです。これは以下のような簡単な数式で表すことができます。
$$ c = \sum_i w_i \times h^{en}_i $$
このcを Context vector と呼び、このベクトルがAffine層への入力の一部になります。
このAttention層には学習すべきパラメータが1つも存在しません。また、このように二つの時系列データ(今回の場合、日本語と英語の文章)を使用して行うattention mechanismを Cross-attention と呼びます。これについては2.4節で詳しく説明します。
2.3 query-key-value
ここで少し脱線します。
データベースには有名な「リレーショナルデータベース(RDB)」以外に「キーバリュー型データベース」と呼ばれるものがあります。前者がテーブル形式でデータを格納します。それに対して後者は保存したいデータ(バリュー)に対して一意の識別子(キー)を設定し、キーとバリューの組で格納します。つまり「キーバリュー型データベース」では、プログラムにおける連想配列のようなデータ構造でデータを格納します。そしてデータベースのユーザーはクエリーを発行し、dbmsはそれを元にキーを探索しバリューを返します。
なぜこのような話をしたかというと、さっき説明したattentionのメカニズムが「キーバリュー型データベース」と似ているからです。
先ほどの重みを計算する際に用いた $h^{de}_t$と$\bm{h^{en}}$ をそれぞれクエリ $Q$、キー $K$に 、重み付き和を計算する際に用いられる $\bm{h^{en}}$ をバリュー $V$ と置いてみます。今回の場合 $K$ と $V$ には同じベクトル(行列)が用いられていますが、必ずしも全てのattention mechanismでそういうふうに実装されているというわけではありません。attentionで行っていたことは、デコーダがクエリQを発行し、エンコーダがクエリを元にキーKを検索し、必要な値(バリュー)を返しているということです。「キーバリュー型データベース」と行っている処理との類推でattentionの理解が多少深まったのではないでしょうか。注意すべき点は、データベースの場合は返す値が唯一つの要素のみであるのに対して、attentionではクエリとキーから関連度を求めて各要素の重み付き和で返していて異なる点のみです。
2.4 Self-attention(Intra-attention)とCross-attention(External-attention)
Attention mechanismはSeq2Seqのみで用いられる機能ではありません。時系列データのどの部分に注意するかを決定する機構全般を指します。Attentionはどのようにして注意する要素を決定するかによって2つに分類することができます。
1つ目は Cross-Attention (交差注意機構) です。Seq2Seqに使用したAttentionはこれに分類されます。Cross-attentionでは2つの時系列データ$v_1, v_2$を用います。2.2節の場合、$v_1$ は日本語の文章、$v_2$は英語の文章でした。2つの時系列データからQ, K, Vをそれぞれ計算し、どの要素に注意するかを決定するのがCross-attentionです。Transformerではデコーダ部分における2つ目のAttention mechanismである「Multi-head Attention」で使用されています。
2つ目は Self-attention(自己注意機構) です。ひとつの時系列データを対象としたAttentionです。ひとつの時系列データ内において各要素が他の要素に対してどのように関係しているかを計算します。つまりQ, K, Vが同じ時系列データから計算された値となります。Transformerではエンコーダ部分の「Multi-head Attention」とエンコーダ部分の「Masked Multi-head Attention」で使用されています。論文ではSelf-attentionについて次のように説明されていました。
「In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder.」
つまり、ある時系列データ$v_1$に対して、別の時系列データ$v_2$を用いて注目すべき要素を見つけるのか、その時系列データ自身$v_1$を用いてどこに注目すべきかを決定するのかという違いがあります。Cross-attentionとSelf-attentionで処理に違いはほとんどなく、Transformer内においては用いているQ, K, Vが異なるだけです。
2.5 Scaled Dot-Product Attention
この章ではTransformerで用いられているAttentionについて説明します。
RNNを用いたSeq2Seqでは、再帰計算により隠れ状態を求めてcontextualized embeddings(文脈埋め込み)を獲得していました。Attentionを用いたSeq2Seqにおいても隠れ状態を求めるのに再帰計算を行う必要がありました。
再帰計算には問題があります。T番目の隠れ状態$h_T$を計算するためには、その時点までの隠れ状態$h_0, h_1, ..., h_{T-1}$の全てを計算している必要があります。つまり時系列方向での計算の並列化が困難です。
Transformerでは再帰計算を行わず、Attentionのみを利用して文脈埋め込みを獲得します。後ほど説明しますがAttention層での処理は行列積が主です。そのため並列化による高速化がとても容易であり、学習時間の短縮を行うことができます。
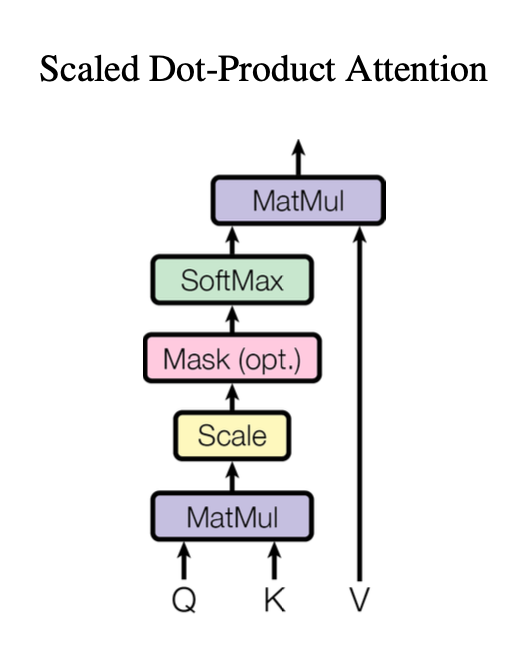
図2.5.1はScaled Dot-Product Attentionの処理を図示したものです。
クエリ、キー、バリューはトークン埋め込み $X$ に対して、それぞれ独立した線形変換$W_Q, W_K, W_V$を施すことにより生成されます。入力文章のトークン数を$N_{input}$とすると埋め込みベクトル$X$は$N_{input} \times d_{model}$次元の行列となります。論文では$d_{model} = 512$とされています。また、クエリ($Q$)、キー($K$)、バリュー($V$)は全て$N_{input} \times d_{model}$次元となっています。つまり各トークンに対して$d_{model}$次元のクエリ、キー、バリューベクトルが生成されます。
$$Q=XW_Q, K=XW_K,V=XW_W $$
Scaled Dot-Product Attentionでは、QueryとKeyの類似度を行列積(Dot-Product)で計算し、その結果を $\frac{1}{\sqrt{d_k}}$ で縮小(Scaled)させ、Softmax関数に通すことで0から1の範囲に限定された重みを計算します。スケーリングする理由は、内積の絶対値が大きな値になりすぎることを防ぐためです。先ほど紹介したSeq2Seqで用いたAttention機構とほとんど同じです。数式では以下のようになります。
$$ \text{関連度スコア S} = \frac{QK^T}{\sqrt{d_k}} $$
$$ \text{Attention}(Q, K, V) = \text{Softmax}(S)V $$
関連度スコア$S$のi行j列目の要素$s_{ij}$の値はi番目のトークンからみたj番目のトークンの関連度となります。この値はiとjに関して非対称、つまり必ずしも$s_{ij} = s_{ji}$が成り立つとは限りません。
class ScaleDotProductAttention(torch.nn.Module):def __init__(self):super().__init__()self.softmax = torch.nn.Softmax(dim=-1)def forward(self, Q, K, V):d_model = Q.size(-1)scores = torch.bmm(Q, K.transpose(1, 2)) / sqrt(d_model) # [batch_num, token_num, d_model]weights = self.softmax(scores) # [batch_num, token_num, d_model]output = torch.bmm(weights, V) # [batch_num, token_num, d_model]return output
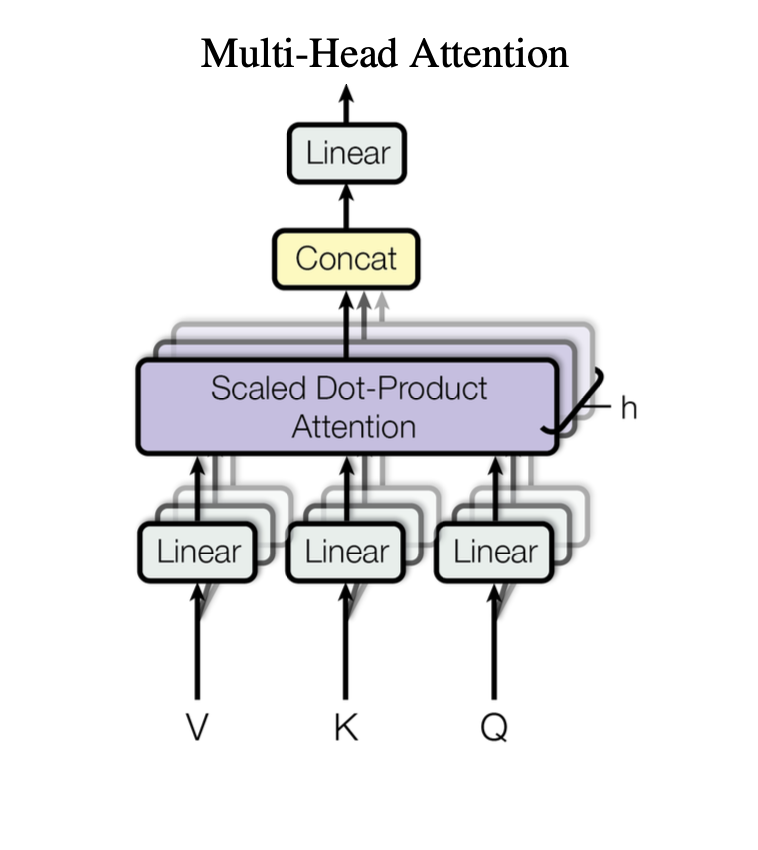
2.6 Multi-Head Attention
Transformerでは表現力をさらに高めるためにマルチヘッドを用います。CNNにおいて、画像の複数の特徴を捉えるために複数のフィルターを用いるのと似ています。
先ほどの説明では各トークンに対して$d_{model}$次元のクエリー、キー、バリューベクトルを生成していました。しかし論文の3.2.2節の以下の文章によると、$d_{model}$次元のベクトル一つを生成するのではなく、$h=8$分割します。例えばクエリの場合、$QW_i^{Q}$, $W_i^{Q} \in \mathbb R^{d_{model}} ×d_{model} $と線形変換することで分割します。
「Instead of performing a single attention function with $d_{model}$-dimensional keys, values and queries, we found it beneficial to linearly project the queries, keys and values h times with different, learned linear projections to $d_k$, $d_k$ and $d_v$ dimensions, respectively.」
最終的なMulti-Head Attentionは次のようになります。
$$ \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) $$
$$ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W^O $$
分割してAttention処理された$head_i$は結合(concat)され、さらに線形変換もなされます。図2.6.1は以上の処理を図示したものです。
このように分割する理由は、モデルが複数の視点を持つことができるからです。つまり文章の「文法的な関係」や「意味的な関係」といった複数の特徴を捉えることができます。Attention Headが一つの場合(分割しない場合)は、情報が一つのベクトルにまとめられてしまう平均化により、文章の複数の側面を捉えることは困難です。
class AttentionHead(torch.nn.Module):def __init__(self, d_model, head_dim):super().__init__()self.W_Q = torch.nn.Linear(d_model, head_dim, bias=False)self.W_K = torch.nn.Linear(d_model, head_dim, bias=False)self.W_V = torch.nn.Linear(d_model, head_dim, bias=False)def forward(self, Q, K, V):scaled_dot_product_attention = ScaleDotProductAttention()output = scaled_dot_product_attention(self.W_Q(Q), self.W_K(K), self.W_V(V)) # [batch_num, token_num, head_dim]return outputclass MultiHeadAttention(torch.nn.Module):def __init__(self, d_model, head_num):super().__init__()head_dim = d_model // head_numself.heads = [AttentionHead(d_model, head_dim) for _ in range(head_num)]self.W_o = torch.nn.Linear(d_model, d_model, bias=False)def forward(self, Q, K, V):x = torch.cat([attention_head(Q, K, V) for attention_head in self.heads], dim=-1) # [batch_num, token_num, d_model]output = self.W_o(x) # [batch_num, token_num, d_model]return output
3. Position-wise feed-forward
Position-wise feed-forward layerの入力と出力の次元はいずれも$d_{model}=512$と等しいです。また中間層の次元は$d_{model}$の4倍である2048です。つまり $W_1: 512\times2048, W_2: 2048\times 512$ となります。
この層では、各トークンはそれぞれ入力列から独立しています。つまり、別のトークンの埋め込みを計算に利用するAttention層とは異なり、入力された位置のトークンのみに閉じて計算されます。
Transformerで使用されている活性化関数はReLU関数ですが、別のモデルではGELU関数が使用されることもあります。
$$ \text{FFN} = max(0, xW_1 + b_1)W_2 + b_2 $$
4. Embeddings と Positional encoding
この章ではエンコーダ層やデコーダ層に入力される値について説明します。
4.1 トークン埋め込み
機械翻訳の対象である文章は文字列であるためニューラルネットワークでうまく扱えません。前回の記事でも紹介した通り、トークンをone-hotベクトルに直した後に変換される埋め込みベクトル$e_i$を利用します。つまり入力された各トークンに対してトークン埋め込みを計算する必要があります。得られる各トークン埋め込みの次元は$d_{model} = 512$です。
4.2 位置埋め込み
Seq2Seqを用いる場合は、隠れ状態を時系列順に再帰計算することによって位置情報を考慮することができていました。しかしAttention(Multi-Head Attention)だけでは「文章中のトークンの位置」を考慮することはできないです。Attentionで行われる処理は、行列積の計算を複数回行って重み付き和を得ているに過ぎないからです。つまり入力のトークン列の順序が変わった場合、対応する出力の順序も同じように変わってしまいます。
この問題を解決するためにTransformerでは、エンコーダ層・デコーダ層への入力であるトークン埋め込みに、あらかじめ位置情報を付与しておきます。
この論文で紹介されたモデルでは、sin関数やcos関数を位置符号としてトークン埋め込みの各要素に加算します。位置符号 $PE(pos, i)$ をpos番目・i次元目のトークン埋め込み $X[pos][i]$ に加えます。
$$ PE_{(pos, 2i)} = sin(\frac{pos}{10000^{2i/d_{model}}}) $$
$$ PE_{(pos, 2i+1)} = cos(\frac{pos}{10000^{2i/d_{model}}}) $$
$d_{model} = 512$ の場合、トークン埋め込み $X[pos]$ に加える位置符号のベクトル$p_{pos}$は次のようになります。
$$ \begin{bmatrix}
\\
sin(pos) \\\\
cos(pos) \\\\
sin(\frac{pos}{10000^{2/512}}) \\\\
cos(\frac{pos}{10000^{2/512}}) \\\\
\vdots \\\\
sin(\frac{pos}{10000^{510/512}}) \\\\
cos(\frac{pos}{10000^{510/512}}) \\\\
\end{bmatrix} \quad $$
sin関数をposの式として見た時、次元が大きくなるごとに波長は $2 \pi$ から $10000 \cdot 2\pi $ まで大きくなっています。
この方法では位置情報を付加するのに必要な学習パラメータはありません。しかしBERTなど別の言語モデルでは位置符号も学習可能なパラメータとして実装することがあります。これに関してはまた別の記事で紹介しようと思います。
最終的に副層へ入力するpos番目のトークンの埋め込みは次のようになります。
$$ x_{pos} = \sqrt{d_{model}} e_{pos} + p_{pos} $$
5. 学習を安定化させる様々な仕組み
Transformer特有の機能ではありませんが、学習を安定化させるための仕組みがいくつか存在します。この章ではそれらの機能について説明します。
5.1 residual connection
residual connectionとは残差結合と呼ばれる仕組みです。
一般にニューラルネットワークが深くなればなるほど勾配消失や勾配爆発が起きやすくなります。つまり入力層に近い層のパラメータの学習が適切に行われなくなります。残差結合を使用すると、誤差逆伝播時に浅い層にも適切な誤差が渡されるようになります。
図5.1.1のような構造のネットワークを例に説明します。F(x)で写像を行う層Lに入力されるxを、Lを通った後に足し合わせます。
$$ y = F(x) + x$$

残差結合は各副層の前後に設置されます。
5.2 LayerNorm
LayerNormは層正規化と呼ばれる仕組みです。こちらも勾配消失や勾配爆発をある程度防ぐことができると考えられています。また、各副層からの出力が小さすぎたり大きすぎたりしても、この仕組みによって対処することができます。xを各段階での埋め込み($d_{model}$ 次元のベクトル)とし、$\mu, \sigma $ をそれぞれxの平均及び標準偏差とします。このxにLayerNormを適用すると次のようになります。
$$ LayerNorm(x) = g \frac{x - \mu}{\sigma + \epsilon}+b $$
$\epsilon$ は微小値であり、gとbはともに学習可能なパラメータであり、ベクトル形式です。
LayerNormはTransformerにおいて各副層(残差結合も含める)の後ろに設置されます。
5.3 Dropout
ドロップアウトは過学習を防ぐための仕組みです。モデルのロバスト性を高めるために、学習時に確率$P_{drop} = 0.1$に従ってランダムにパラメータの値を0にして無効化します。
Transformerにおいては以下の4つの場所で使用されています。
入力埋め込み
$$ Dropout(x_{pos}) $$
マルチヘッド注意機構の重み
$$ Dropout(Softmax(QK^T / d_k)) $$
残差結合による加算を適用する前のマルチヘッド注意機構の出力
$$ Dropout(MultiHead(Q,K,V)) $$
残差結合による加算を適用する前のフィードフォワード層の出力
$$ Dropout(ReLU(W_1 x+b_1 )W_2 +b_2) $$
6. Encoder
ここで再びエンコーダの構成について見てみましょう。
Encoderでは以下の処理を順に行います。
1. Input Embedding
- 入力トークン列からトークン埋め込み$e_{en}$を生成します。この段階では文脈も位置も考慮されていない埋め込みです。
2. Positional Encoding
- トークン埋め込み$e_{en}$に対して位置符号$p$を加算します。
3. Encoder Layer $\times N_x(=6)$
- 埋め込み列$\bf{x_{en}}$に対してMulti-Head Attention及びFeed Forwardを適用します。
- Multi-Head AttentionはSelf-attentionです。
- Feed ForwardはPosition-wise feed-forwardです。
Encoderは最終的に文脈埋め込み$c_{en}$を出力します。
class EncoderMultiHeadAttention(torch.nn.Module):def __init__(self, d_model, head_num):super().__init__()self.W_Q = torch.nn.Linear(d_model, d_model, bias=False)self.W_K = torch.nn.Linear(d_model, d_model, bias=False)self.W_V = torch.nn.Linear(d_model, d_model, bias=False)self.multi_head_attention = MultiHeadAttention(d_model, head_num)def forward(self, x_en):Q = self.W_Q(x_en) # [batch_num, token_num_en, d_model]K = self.W_K(x_en) # [batch_num, token_num_en, d_model]V = self.W_V(x_en) # [batch_num, token_num_en, d_model]output = self.multi_head_attention(Q, K, V)return output
7. Decoder
次にデコーダの構成について見て見ましょう。
Decoderでは以下の処理を順に行います。
1. Output Embedding
- 出力トークン列からトークン埋め込み$e_{de}$を生成する。Encoderの場合と同様です。
2. Positional Encoding
- 各トークン埋め込みに対して位置符号を加算する。Encoderの場合と同様です。
3. Decoder Layer $\times N_x(=6)$
- 埋め込み列$\bf{x_{de}}$に対してMulti-Head Attention(Self-attention)、Multi-Head Attention(Cross-attention)及びFeed Forwardを順に適用します。
- Multi-Head Attention(Self-attention)では、入力された埋め込み列$\bf{x_{de}}$からキー、クエリー、バリューを生成します。ここでの出力を$\bf{y}$とします。
- Multi-Head Attention(Cross-attention)では、encoderから入力された文脈埋め込み$\bf{c_{en}}$からキーとバリューを、埋め込み列$\bf{y}$からクエリーを生成します。このattentionの役割は2.2節で説明したものと同じです。つまりデコーダがトークンを生成する際に、エンコーダから出力された文脈埋め込みの「文脈」をヒントとしています。
- Feed ForwardはPosition-wise feed-forwardであり、Encoderの場合と同様です。
Decoderの出力は、最後にクラス分類器に入力されます。
class DecoderMultiHeadAttention(torch.nn.Module):def __init__(self, d_model, head_num):super().__init__()self.W_Q = torch.nn.Linear(d_model, d_model, bias=False)self.W_K = torch.nn.Linear(d_model, d_model, bias=False)self.W_V = torch.nn.Linear(d_model, d_model, bias=False)self.multi_head_attention = MultiHeadAttention(d_model, head_num)def forward(self, x_en, x_de):Q = self.W_Q(x_de) # [batch_num, token_num_de, d_model]K = self.W_K(x_en) # [batch_num, token_num_en, d_model]V = self.W_V(x_en) # [batch_num, token_num_en, d_model]output = self.multi_head_attention(Q, K, V)return output
8. Transformerの学習
このモデルを学習する上で取り組んだタスクは「機械翻訳」です。
モデルへの入力はソース言語のトークン列であり、出力はターゲット言語のトークン列です。目的はソース言語で入力されたトークン列を、ターゲット言語のトークン列に変換(翻訳)することです。一回の推論で出力されるトークンは1つのみであり、損失関数は交差エントロピーです。「私はペンを持っている」を"I have a pen"に翻訳する例では、「私はペンを持っている」が入力列でありモデルが"I have a"まで出力している場合、次に"pen"を出力することを期待します。
8.1 Teacher forcing
TFは学習時に使用される仕組みです。学習開始時はモデルの予測精度が良くありません。「私はペンを持っている」から"come that wifi"のようなトークンを予測してしまう可能性があります。ここでモデルは次に"pen"を予測すべきですが、これまでに予測したトークン列"come that wifi"をデコーダの入力としてしまうと期待した予測をしてくれないです。つまりこのまま予測を続けると失敗が積み重なっていきます。そのため学習時の段階ではデコーダへの入力に教師データ(正解データ)である"I have a"を使用します。こうすることで学習を効率よく行うことができます。
8.2 Masked Multi-Head Attention
Decoder内のMasked Multi-head Attention(Self-attention)について説明します。推論時はEncoderにおけるMulti-Head Attentionとほとんど変わらないです。ただし、学習時はカンニングを防ぐために入力の一部(予想するトークンより後ろのトークン)に相当する関連度スコアをマスキングします。
機械翻訳ではソース言語のトークン列$u_1, u_2, ..., u_M$からターゲット言語のトークン列$w_1, w_2, ..., w_N$を1トークンずつ順に予測する。ここでターゲット言語のトークン列の$w_i$までを予測した状態を仮定します。この時$u_1, u_2, ..., u_M$と$w_1, w_2, ..., w_i$から$w_{i+1}$を生成(予測)します。つまりN個のトークンを生成するのにN回計算する必要があります。
学習の高速化のためにTransformerでは、このN回の計算を並列化します。つまりDecoderのSelf-attentionで$w_1, w_2, ..., w_N$全ての関連度を同時に計算することになります。これは$w_1$の文脈埋め込みを計算する際に問題が発生します。当たり前ですが、$w_2$を推論する際に$w_2$というトークンをモデルから見ることはできません。しかし学習時にはTeacher forcingの仕組みを使用するため、並列化を行うと$w_1$の文脈埋め込みの計算に$w_2$の埋め込みを使用してしまいます。これはカンニングしていることと同じです。
カンニングを防ぐために関連度スコア$s_{12}$の値を$- \infty$ に設定します。この時$Softmax(S)$の1行目2列目の要素の値は極めて小さくなります。ゆえに$w_1$の文脈埋め込みを計算するのに$w_2$の影響はほとんど無視することができます。一般に関連度スコア$S$の値は$i < j$の場合$s_{ij} = -\infty$とすることでマスキングを行います。
9. まとめ
1章ではTransformerのアーキテクチャを示し、2~5章ではTransformerで使用されているコンポーネントについて詳しく説明しました。6, 7章ではこれらのコンポーネントを使ってEncoderとDecoderを構成しました。最後に8章では並列化などの学習時に使用するテクニックについて紹介しました。
Transformerは当時のベンチマークを更新しただけではありません。それ以降のAIモデル(GPTやBERT)のベースとして未だ活躍しています。これらTransformerベースのAIモデルを今後の記事で紹介したいと思います。
この記事を最後まで読んでいただきありがとうございます。次の記事でまた会いましょう!
Share



Author
芝 紘希
ソフトウェアエンジニア
現在は神戸大学工学部情報知能工学科に在籍し勉強中です。ただただひたむきに筋肥大。